Desi R. Ivanova
Desi R. Ivanova
Home
Publications
Posts
Talks
Contact
Posts
Some thoughts on the role of Bayesianism in the age of Modern AI
Bayesian methods have undeniable value, e.g. in data analysis, but they play a peripheral role in “Modern AI” (i.e. deep learning), which prioritises scalable, empirical approaches over theoretical grounding—a trend that is unlikely to change.
Desi R. Ivanova
Last updated on 29 Dec, 2024
1 min read
ML
Towards more rigorous evaluations of language models
As language models become increasingly sophisticated and existing benchmarks approach saturation, the need for rigorous evaluation methods grows more pressing. Many evaluations lack the statistical rigour needed to draw meaningful conclusions, leading to a potential over-confidence in results that might not hold up under scrutiny or replication. This post advocates for bringing fundamental statistical principles to language model evaluation, demonstrating how basic statistical analysis can provide more reliable insights into model capabilities and limitations.
Desi R. Ivanova
,
Ilija Ilievski
,
Momchil Konstantinov
Last updated on 29 Dec, 2024
33 min read
ML
On Some (Fixable) Limitations of 'Understanding the Limitations of Mathematical Reasoning in LLMs'
There is huge value in developing new benchmarks and I think the one that proposed in the paper ‘GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models’ by Apple is quite neat and useful! The accompanying analysis, in my opinion, can be substantially improved with the help of basic statistics. Without those we risk over-interpreting results and drawing misleading conclusions. I never thought I would be the one advocating for the use of hypothesis tests and p-values, but here we are… When it comes to language models evals, it is time to make statistics great again!
Desi R. Ivanova
Last updated on 29 Dec, 2024
14 min read
ML
Bayesian Experimental Design in BayesFlow
A simple tutorial on how to implement static BED in BayesFlow
Desi R. Ivanova
Last updated on 22 Oct, 2024
1 min read
ML
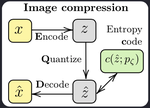
Introduction to Neural Compression
Machine learning, and deep probabilistic modelling specifically, seems to be revolutionising the space of data compression. This short post describes 1) the basic components of the data compression pipeline; 2) the objective used to optimise model parameters and its equivalence to training a VAE; and 3) some of the challenges that need to be solved.
Desi R. Ivanova
Last updated on 18 Feb, 2022
7 min read
ML
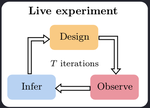
Introduction to Bayesian Optimal Experimental Design
Bayesian Optimal Experimental Design (BOED) is an elegant mathematical framework that enables us to design experiments optimally. This introductory post describes the BOED framework and the computational challenges associated with deploying it in applications.
Desi R. Ivanova
Last updated on 22 Nov, 2021
7 min read
ML
Cite
×